
About me
Welcome! I am an assistant professor in the Department of Industrial Engineering and Management Sciences (IEMS) and the Department of Mechanical Engineering (ME) at Northwestern University, where I lead the Integrative AI (IAI) Lab. I obtained my Ph.D. from the Department of Industrial and Operations Engineering at the University of Michigan. The research in our lab is driven by the need for novel AI and statistical methodologies addressing scientific and engineering challenges across diverse domains, including Digital Twins and smart manufacturing. We are also interested in investigating the theoretical underpinnings of these methods. In particular, our current research in personalized and generative data analytics explores computational techniques to integrate knowledge from multiple sources.
Featured papers
A few topics of my research are introduced below.
DiffATS: Diffusion in Aligned Tensor Space Jinhua Lyu, Tianmin Yu, Brian Kim, Lizhuo Zhou, Chanwook Park, Naichen Shi, 2026. Link, Code.

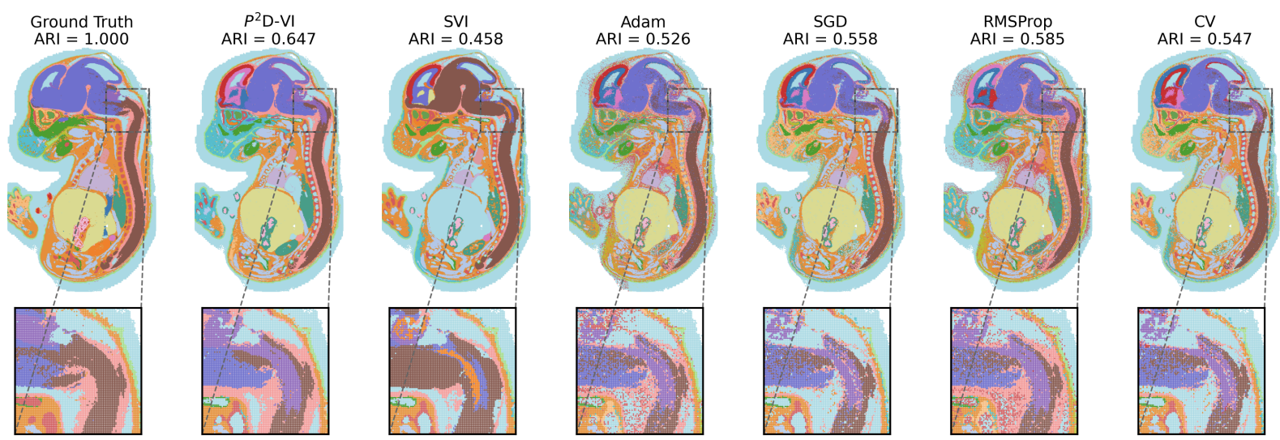
Scalable Mean-Field Variational Inference via Preconditioned Primal-Dual Optimization Jinhua Lyu, Tianmin Yu, Ying Ma, Naichen Shi, 2026. Link.
Here is a more comprehensive list of publications. You can also check my Google scholar profile.
Recent news
- May 2026: Jinhua won the NSF ACCESS Graduate Compute Award!
Previous news
- May 2025: Our paper, "Calibrated Principal Component Regression," is accepted by AISTATS 2026!
- September 2024: Our paper, "Triple Component Matrix Factorization: Untangling Global, Local, and Noisy Components," is selected as the winner for the Data Mining best paper competition in INFORMS, 2024!
- June 2024: Our paper, "Triple Component Matrix Factorization: Untangling Global, Local, and Noisy Components", won the Wilson prize!
- October 2023: Our paper, "Personalized Tucker Decomposition: Modeling Commonality and Peculiarity on Tensor Data", is selected as the finalist of the INFORMS 2023 QSR best refereed paper competition!
- October 2023: Our paper, "Heterogeneous Matrix Factorization: When features differ by datasets", is selected as the finalist of the INFORMS 2023 best student paper competition!
- July 2023: I am selected as the instructor of the small course of IOE 202 Operations Engineering and Analytics!